
Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs).
To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
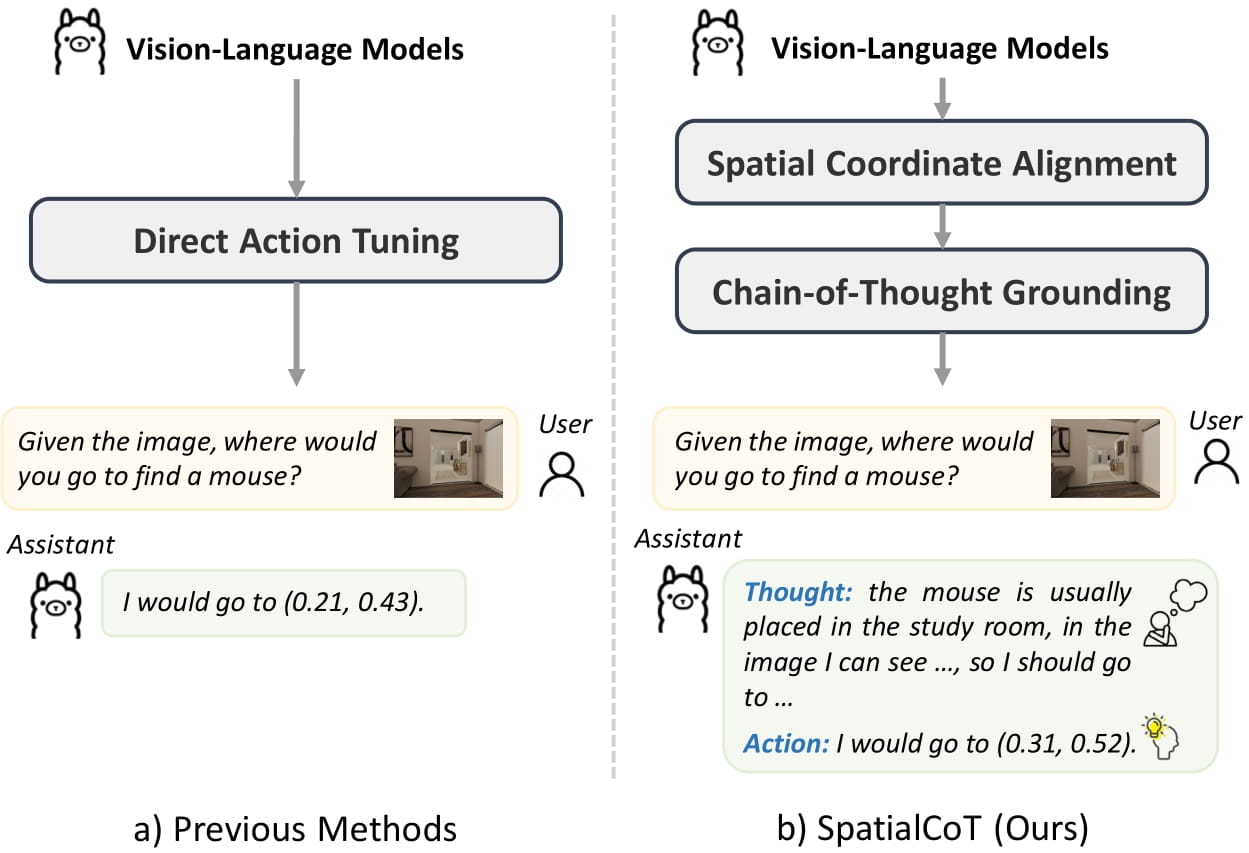
Comparison between SpatialCoT and previous methods. a) Previous methods usually directly output the action based on the language instruction. b) SpatialCoT enhances action generation quality by effectively leveraging the reasoning capabilities of VLMs. This is achieved through a two-stage finetuning process involving spatial coordinate alignment and chain-of-thought spatial grounding.
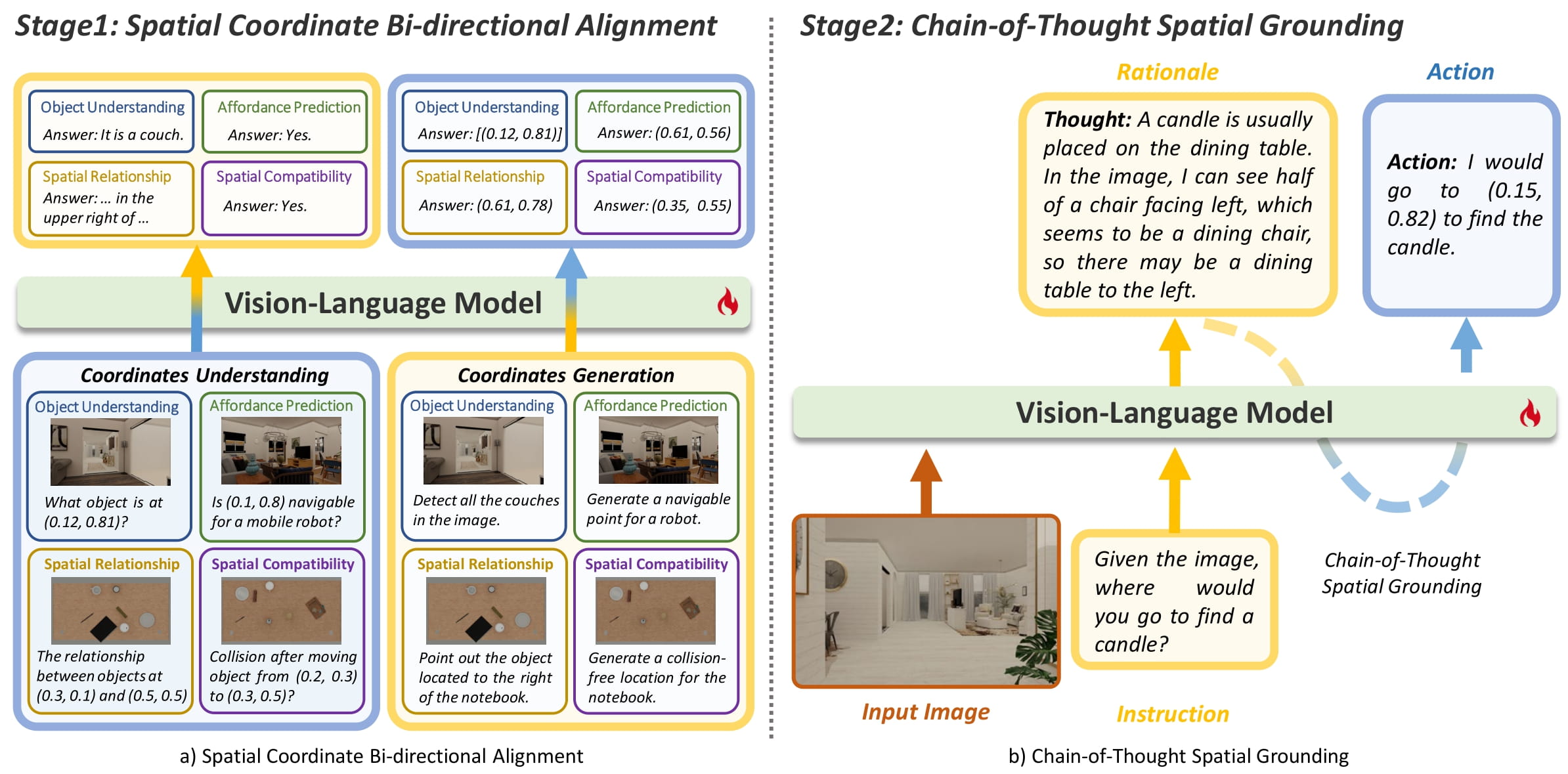
Overview of SpatialCoT, comprising two core stages. a) Spatial coordinate bi-directional alignment, which involves translating coordinates to language (indicated by the blue to yellow arrow on the left) and language to coordinates (indicated by the yellow to blue arrow on the right). b)Chain-of-thought spatial grounding: the model first performs comprehensive thinking by generating a language-based rationale, and then grounds it in coordinate-based actions (yellow to blue dashed line), significantly improving the model's performance in complex spatial reasoning tasks.
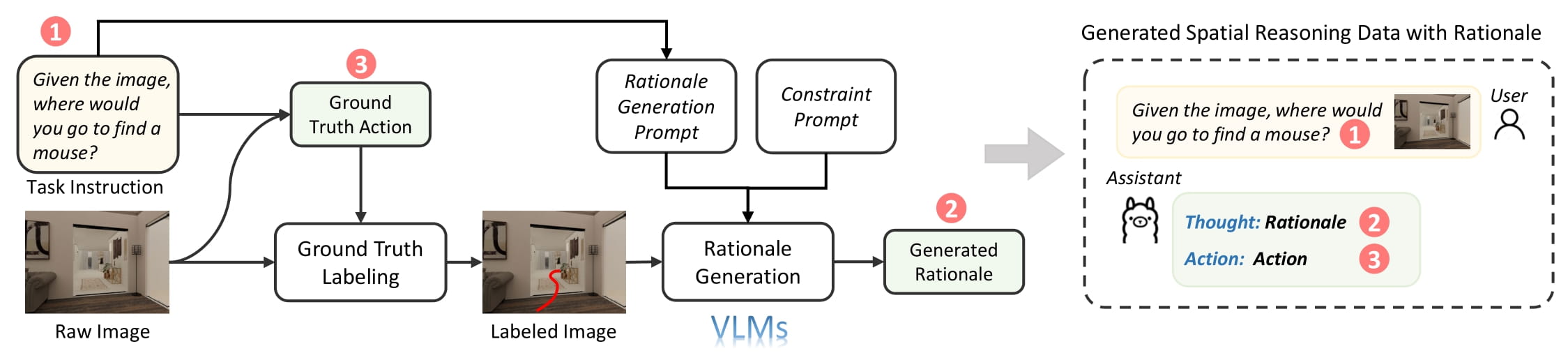
Pipeline for collecting high-quality rationale-action data pairs: shown in the Figure. First, a ground truth action is generated from a simulator using a rule-based approach, ensuring its optimality. This action is then annotated on the input image as a trajectory or subgoal point, depending on the task. Next, a vision-language model generates a rationale based on the annotated image and task instruction. To prevent information leakage, we include a constraint prompt, such as “Your output should not include the ground truth action,” ensuring the rationale’s validity.
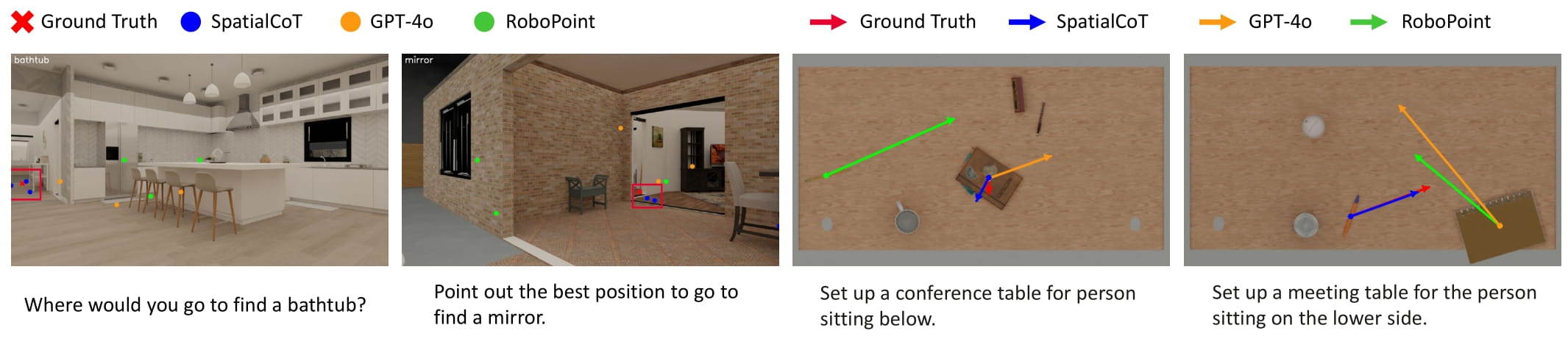
Visualization of spatial reasoning results on navigation and manipulation tasks.
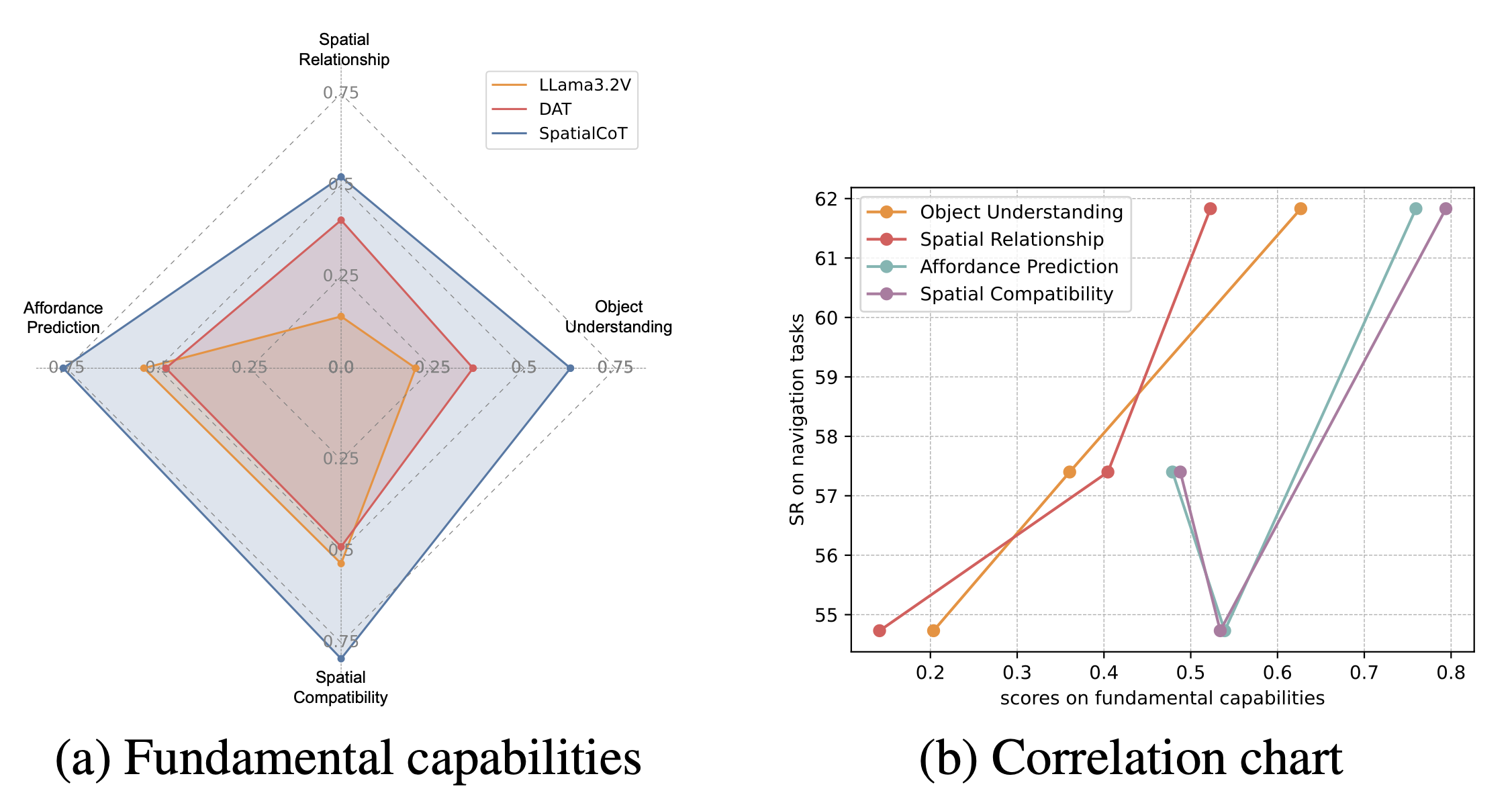
In our evaluation of the fundamental capabilities of Vision-Language Models (VLMs), we find that SpatialCoT consistently outperforms other models across all evaluated categories (see Figure a). To further explore the correlation between each category of fundamental capability and downstream performance, we present these correlations in Figure b}. The horizontal axis represents the scores of fundamental capabilities, while the vertical axis shows the success rates in embodied planning tasks. Each line corresponds to a specific category of fundamental capability. The results reveal a clear positive relationship between object understanding and spatial relationships (orange and red lines). The other two categories also display a positive correlation trend, though not entirely monotonic. These findings demonstrate that there is a positive correlation between the fundamental capabilities of VLMs and their downstream performance, providing a valuable basis for further research in this field.

Experimental results demonstrate that the chain-of-thought process significantly enhances the model's ability to utilize spatial and contextual information, such as room layout and commonsense knowledge, to arrive at the correct answer. To illustrate this, we present a case study (see Figure). In this task, the model is instructed to locate an alarm clock within a house. The SpatialCoT model first considers the typical location of an alarm clock, infers the bedroom's position based on the current layout, and ultimately produces accurate results. In contrast, the baseline model (without CoT) generates disordered results throughout the room.
The experimental results on the first row are from SpatialCoT, and the results on the second row are from GPT4o. SpatialCoT can take physical constraints into account by first relocating occupied items to available space, and then placing the plate in a reasonable position. In contrast, GPT4o fails to accurately understand these constraints, directly placing the plate in the target position, which leads to physical collisions.
@inproceedings{arxiv2025,
title = {SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning},
author = {Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, Helong Huang, Guangjian Tian, Weichao Qiu, Quan, Jianye Hao, Yuzheng Zhuang},
year = {2025},
booktitle = {arxiv 2025}
}